Another cool geospatial web 2.0 app about climate change impacts of sea level rise.
Archive for March, 2012
Climate change apps
Saturday, March 17th, 2012Oh, those young people
Saturday, March 17th, 2012Young people not so green after all. That’s bad for impacting climate change.
Is this true?
“But I still find myself pretty frustrated a lot of the time,” said Stokes [, a 20-year-old geography student at Western Washington University], who wants to go into marine resource management. “I just think our generation seems fairly narcissistic — and we seem to have the shortest attention span.”
Kelly Benoit, a 20-year-old political science student at Northeastern University in Massachusetts, went as far as calling her peers “lazy.”
“I think it can be due to our upbringing. We want what we want when we want it,” said Benoit, who has worked with lawmakers in her state to try to ban the use of plastic bags in stores.
She thinks members of her generation, like a lot of people, simply don’t want to give up conveniences.
Perhaps we need to tie environmental issues to KONY2012 somehow (although that’s what I was hoping from Inconvenient Truth).
Coarse grained data issues low resource settings
Friday, March 16th, 2012Despite Goodchild et al.’s (1998) article’s technical components, the article did make me think of uncertainty regarding boundaries and course grained satellite imagery. Exploring low resource settings on Google Earth is one such example. Although an incomplete geolibrary, I consider Google Earth to be effective in its user friendly interface and features (layers and photographs), and of course, ubiquity. It’s a start. With this in mind, ‘flying’ over towns in Colombia on Google Earth, and the terrible, terrible satellite imagery that was available. (The low quality imagery remains unchanged since the last time I checked it half a year ago). One of the towns/districts is Puerto Gaitan. How do we account for the lack of resources given to collecting fine grained even medium grained visualizations?
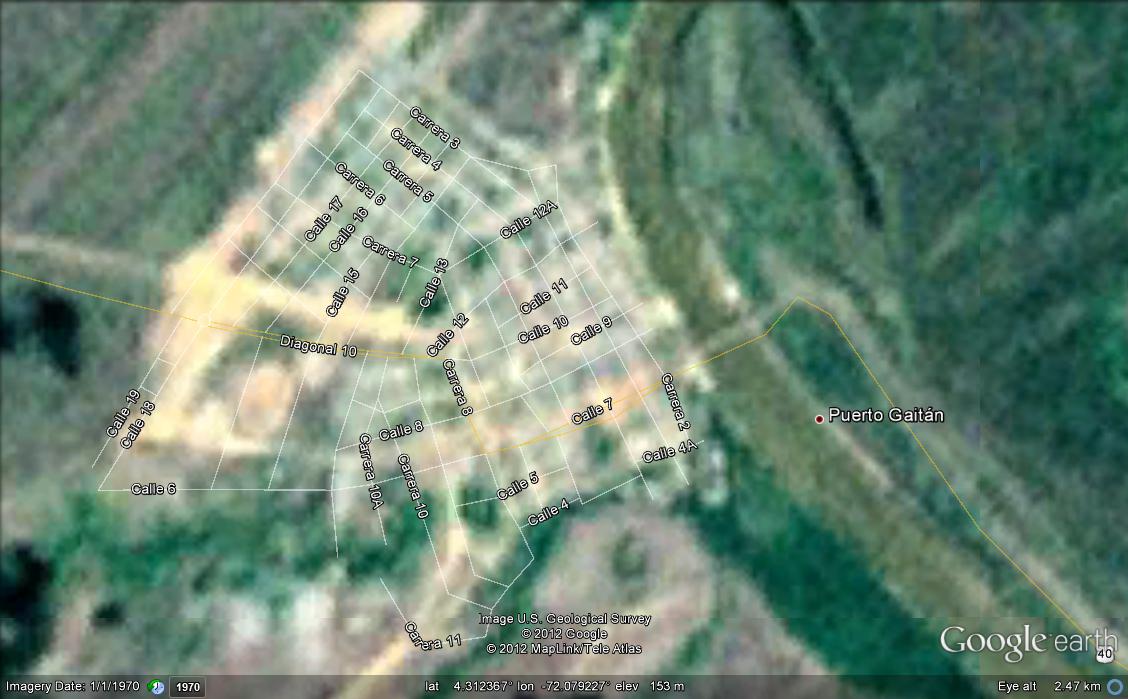
According to Goodchild et al., alternative methods for displaying fuzzy regions must be applied where cartographic techniques are not enough. “A dashed region boundary would be easy to draw, but it would not communicate the amount of positional uncertainty or anything about the form of the z(X) surface” (208). What do we do then, when the data cannot even be analyzed because it is too coarse? For low resource settings, we are just going back to where we started. No financial incentives to improve data (from coarse to fine) = continuation of coarse grained data = poor visualization = cannot be utilized in studies = no advancements in research are made = back to the start, no financial incentives to improve the quality of data. How do we break this cycle?
-henry miller
Footprints and priorities
Friday, March 16th, 2012Goodchild’s (1998) ‘Geolibrary’ chapter is a great introduction to the geolibrary field and the challenges it poses. However, it should be noted that it was published 14 years ago, which may mean that some of the questions raised have already been answered, while others still remain problematic, and further, new questions are anticipated. In particular, geographical footprints have become more complex in search queries. “But the current generation of search engines, exemplified by Alta Vista or Yahoo, are limited to the detection and indexing of key words in text. By offering a new paradigm for search, based on geographic location, the geolibrary might provide a powerful new way of retrieving information” (2). Now that we have Google as the most used search engine, I agree with Jeremy regarding his reference to Google Maps and searches related to businesses. I believe it is a type of geolibrary, although the economic and legal issues that Goodchild poses come to mind (8). As Google as a business the payment for its maintenance and the legal rights it holds become convoluted and at times questionable to the users. Would open-source map applications such as OpenStreetMap be more appropriate to manage financial and legal issues with fewer controversies?
Geolibrary footprints continue to be interesting due to its ability to enhance or hinder the amount of sources a user is exposed to. The more in the vicinity a user is to the specific location they are researching and want to extensively explore the database of a particular geolibrary, the more information that individual will find. This can be problematic for remote researchers that are constrained to a geographical location, and at a great distance from their research study area. This can have serious implications on the research conducted as the way the research unfolds drastically alter based on the amount of sources available. In a sense, it is stifling the global aspect of geolibraries as a plethora of sources about a location is still only available in the proximity of the location in question. As the questions a geolibrary can answer revolve around area, geographical footprints can play a significant role to diminish uneven distribution of place related information in a digital form.
-henry miller
Geolibrary implementation
Friday, March 16th, 2012In the chapter 5 section by Goodchild, he goes over how a geolibrary would work conceptually. However, I think there are some problems already brought up in his description. I don’t think that having server catalogues where a server is in the possession of one (or multiple) specialised collection is necessarily a good idea. It doesn’t sound very efficient to me. The thing about data is that there isn’t equal demand for it everywhere. Some data is demanded more than others (more people search for the weather at a given location than say, the demographic composition of it). Therefore, if you restrict servers to having only a certain kind of specialised content, you would not be optimising your server loads. Instead, you’d get a bunch of servers that have very low traffic that isn’t cost effective, and maybe more servers for which traffic is so high that you need to expand them. I just got the feeling that the suggestion was to model the hardware layout after the layout of the data, but this is just going to be inefficient. It means more connections have to be made, maybe more servers (and the extra costs associated with that), and probably slow performance.
The kind of system being described doesn’t sound very future-proofed. It’s like our ontology discussion. What happens when a new category is created? What happens when a sub-category becomes more important or separated from it’s original category?
In the article on fuzzy spatial queries, I think it is easy to say that we need to be able to form a method of querying that can incorporate both defined an badly defined regions, but how could this ever be compatible with the chapter 5 description of how the library would actually work? I think that ill-defined regions are just that, and I think the best we can do is just use a search engine. If we try to structure it (as we must do if we want specialised servers), then we run into all sorts of problems I think you all have an idea about.
Finally, I’m getting the feeling that we are meant to start our queries in a geolibrary with a location (well defined or not). It seems that geolibraries would be tailored for a certain flow of querying (location > topic > sub-topic > person etc.). What if we don’t want to start our query with a location?
He’s talking about AltaVista….AltaVista people. Remember them? No? That’s because they’re dead.
-Peck
A Tangent from Fuzzy Footprints…
Thursday, March 15th, 2012Goodchild’s (somewhat uncoordinated) introduction to Fuzzy Footprints got me thinking, once again, back to ontologies–as has been mentioned by many others posting not only on this topic, but on many topics we have covered in class this semester. So it brought me back to another question asked in class, again with regards to multiple topics: how important is geo-education? And so here I would argue: VERY important.
Uncertainty can be largely down to our ability (or lack thereof) to communicate, and to understand what has been communicated by others. Boundaries, locations, and our ability to define them are essential to geolibraries. If we cannot come to general understandings, there will constantly be error. Before in class I was not convinced that education (about scale, particularly, but about various geographic phenomena) should be made explicit (outside of a geography class). Now, I believe otherwise–how could I not after repeating topic after topic that ontologies (and thus understanding) is important?
To create a global database of georeferenced information is a magnificent endeavour. To create a global database of georeferenced information that can be efficiently searched by any member of the global community is a whole new ballgame, and must necessarily involve a renewed goal of educating the public and of coming to shared understandings (both on areas of agreement and disagreement).
–sah
Geopedia?
Thursday, March 15th, 2012Imagine the first decade of the 2000s, the Internet well-established, and the endless possibilities beginning to emerge in full. The possibilities for data sharing are immense. And then, on January 15th, 2001, it manifested in what is today recognized as an extraordinary project: Wikipedia. Today we know Wikipedia as an oft-reliable source, and while further references are always ideal, it is the perfect starting point for mining the internet of the immense amounts of data it has, as well as exploiting the research already done by many others in the global commons.
This is what came to mind when reading Goodchild’s introduction to Geolibraries. While I first thought of Google Earth, and the basemap it provides upon which to place georeferenced data, the further I read into his overview, the more I thought of Wikipedia, and how this platform seems to be a perfect way to bring the idea of geolibraries to reality. To further elucidate, I will go through a couple of Goodchild’s main questions at the end of his article.
First, he asks about intellectual property rights. Obviously, geolibraries will contain information that is more than just “fact” (in as much as things on Wikipedia are fact), such as musical pieces, building plans, etc that may not in fact be property of the global common. Perhaps copyright as is applied on other internet sharing sites such as Flickr could be a good start–is something a part of the global commons, is it licensed for creative use, or is it 100% copyrighted?
Goodchild also asks about the “infrastructure” of a geolibrary, as well as the economic feasibility. This too could be modelled from Wikipedia–a veritable container of a plethora of information, pictures, sound clips, and more. Wikipedia is founded by the Wikimedia Foundation, a non-for-profit charitable organization–perhaps this is the route geolibraries must take: an endeavour to be undertaken by those passionate about Georeferenced information?
Finally, I would like to address the question of metadata. Goodchild asks how much metadata we need, how it should be catalogued, and elsewhere in the article, he speaks briefly again to a users own cognition. I believe with a “Global Commons” type of platform, like Wikipedia, there will be a lot of metadata, that can be edited continuously by multiple people and perspectives with the hopes of finding a neutral ground.
Obviously there are a lot of ways Wikipedia isn’t directly amenable to becoming a Geolibrary, but this is, in my opinion, an interesting model to start from–going from paper encyclopedias in physical libraries to online catalogues of information.
–sah
Where are all the geolibraries?
Thursday, March 15th, 2012Chapter five by Goodchild provides a good overview to geolibraries, their importance and the components that goes into constructing them. He highlights the difference between geolibraries and traditional physical libraries. Namely, that geolibraries would be more compatible to deal with multimedia content, hold more local information and avoid the issue of duplication. I think today the separation between the digital and traditional library have become much less distinct. Online catalogues allow users to search many libraries at the same time and thus address the problem of duplication to some degree. As more books and other materials are digitized, a user no longer needs to go to the library to get the material he/she needs. I often download newspapers, articles, and magazines from the McGill library. Also we all frequently download maps and GIS data off the Internet especially since many cities have established open data portals. Thus, I argue, the key feature that will make geolibary special is not how comparable it is to physical libraries but how it allows users to discover various topics about a location of choice.
Further, I wonder why geolibraries have not become very popular since 1998 because this is the first time I have heard about them. Maybe it has to do with the 4th research question Goodchild asks: “What institutional structures would be needed by a geolibrary? What organizations might take a lead in its development?” I would also like to add, what kind of personnel training and organizational shift in the ways things gets done are required by current governmental structures to enable the adoption of geolibraries? There is definitely inertia within public office structures that is often difficult to overcome when introducing new technology. Finally, I would like to consider who should be responsible for the data and the limitations of the kind of data offered. I remember Peter telling me that one of the reasons why governments are hesitant to make data public was if the data contained a mistake about an area, who should be held responsibility for the damages? The one who collected the data? The one who entered the metadata? The geolibrary for providing bad data? Also, what kind of limitations should be set on the kind of data downloadable through a geolibrary. For example, restrictions should exist on data that are highly political such as health data or high-resolution environment data.
Ally_Nash
Soft Boundaries, Scale and Geolibraries
Thursday, March 15th, 2012The article by Goodchild et al (1998) mainly dealt with finding a way to figure out to what degree a footprint conceived by the users matches with one that exists in the geolibrary. The difficulty is how to include ill-defined areas into the gazetteer since their boundaries are not precise yet they hold significance in people’s lives. The author sums it up nicely by declaring “effective digital libraries will need to decouple these 2 issues of official recognition and ability to search, by making it possible for users to construct queries for both ill-defined and well defined regions, and for librarians to build catalog entries for data sets about ill-defined regions.” (207). I agree with ClimateNYC. This was the exact problem for researchers building landscape ontology and displaying features that have “gradual” boundaries such as towns, beaches, forests and mountains. Field representations seem a viable option. However, if a neighborhood, for example, have a range of “soft” boundaries, I would argue in favor of having one of the more inclusive one (so that a point that is considered only 30% to be part of Area A will also be included in the query) be taken into consideration by the gazetteer and thus giving the user the opportunity to filter through the data himself.
Hierarchical nature of space is also an interesting topic raised by the authors. Should a search for Quebec also return datasets about Montreal? In addition to listing all well- and ill-defined places, it might also be favorable to separate the datasets into relevant scales. For instance, a user querying Quebec (or even Eastern Canada) is most likely looking for datasets at smaller (cartographic) scales than someone who is querying Montreal. For instance, a search for Eastern Canada in the ADL brought me directly to Fredericton when I would be expecting the whole area between Quebec and Newfoundland. Returning data at the wrong scale would be very inappropriate.
Ally_Nash
Geo-libraries, skyscrapers, and regional bias
Thursday, March 15th, 2012I find the topic of geo-libraries fascinating, particularly because of the incredible potential I think that they have in conveying ideas. It is a very powerful way of organizing information that allows for visual comparisons to be made. For example, related information that may be of use to a user may be more easily suggested or discovered, as information that is geographically related can displayed. The importance of geo-libraries in practice is also backed up, as the majority of map library users rank locational characteristics as the primary search key.
Since I’m a bit of a building/architecture nerd, I think the following is an interesting example of a geo-library:
http://skyscraperpage.com/cities/maps/
Perhaps this is a very simplified version of a geo-library, but it shows how an individual can search for information on proposed, under-construction, and/or competed buildings by selecting a geographic region. As one can see from the map, very useful visual information can be gained through pattern recognition. Clusterings of under construction buildings, for example, are easy to find.
While I think that this is an extremely useful tool, my example is one that may be much more straightforward than those discussed in Goodchild’s article. Most of the cities listed, for example, appear to have well-defined, uncontested boundaries (or perhaps they just appear that way?). Further, the uncertainty present in the information available for each building (location, type, developer, floor count) also seems to be relatively low.
Even though this example may be simplistic, I think that it points to the potential for geo-libraries to have a regional bias. By examining the list of cities available to search, for example, it is clear that this architecture website has a North American focus. However, perhaps technology will enable users to overcome this bias. An example provided by Goodchild is the use of geo-library ‘crawlers,’ which search the web looking for key terms based on geography. Despite their potential, these technologies also bring with them a variety of other problems. For instance, as mentioned by ClimateNYC, the issue of ontologies arises, where incorporating varying opinions and definitions proves to be troublesome.
Perhaps someone can answer this in their blog post, but I am uncertain as to the various forms geo-libraries can take. For example, since users can search for related businesses within a Google Maps map frame, would this be considered a type of geo-library?
– jeremy
Geo-libraries and tourism
Thursday, March 15th, 2012In a geography of Asia class I took last semester, possible ways for individuals to engage in responsible tourism was discussed. Most often, much research was required in order to educating oneself on local conditions or current events. However, sifting through the biased perspectives of local media or governments can be a challenging activity. Especially when trying to understand how tourism impacts marginalized communities, understanding this can be an important factor. I think that a geo-library can facilitate learning in this case, where tourists can query and access information depending on what region they are in. The option of seeking out academic articles can enable people to gain scholarly perspectives that may more accurately represent local conditions.
As the article by Goodchild et al. mentions, however, an issue arises when footprints or terms of searches are ill-defined. With regards to tourism, it would seem that this problem would be magnified in remote areas. For example, as we know from our discussion on ontologies, defining objects is very challenging, especially when multiple languages are being considered. Further, less information is available for remote areas in general and so while geo-libraries may be extremely enabling in many aspects, they may also be limiting for areas not well-represented.
Perhaps an interesting comparison is likening a geo-library to a mental map. While the regions that I best understand will likely have the most amount of detail, it will not include important elements belonging to another individual’s mental map. As Goodchild et al. posit, objects with ill-defined terms that are not well-represented in a geo-library can also be of great significance to the lives of individuals at a local level. In other words, while a place name or building may not appear in a geo-library query (or my mental map), it may still be very relevant to many people. Determining how to incorporate under-represented features will be a challenging, but crucial issue in the development of geo-libraries.
– jeremy
Blickr: Flickr for books!
Thursday, March 15th, 2012Goodchild touches on a few interesting thoughts in the second article. I feel however, that this article is outdated. He refers to being able to access information across a network as something almost magical. He says something along the lines of a georeferenced library will have the ability to serve people across the globe using digital copies! On a similar note Goodchild also mentions the idea of not needing to duplicate material—an idea that we seem to be unable to escape from in each of our lectures.
Something that I found quite relevant however, is the sorting and cataloguing of photographs . The geolibrary offers a much more concrete system of organization. I really love this idea. Prior to the concept of a geolibrary I can only assume that if photographs were not assembled in a portfolio, compilation with a specific topic or in published book, it might be hard to find photos. Even within a publication, it seems like a tedious task to track down a photo that is most probably untitled and not georeferenced. I think that Flickr currently does a decent job at this task, but this database is limited to photographs only. As a user you can label your photos, add description and even add georeferenced data to help other users search for photos, as they might search for academic articles. The collection of photos, by user, visualized on a map is stimulating. Not quite as useful as I proposed in my other blog post, but still pretty cool.
I found this article somewhat repetitive, and perhaps unnecessary, but did address some fundamental reasons for and problems with geolibraries. I’m eager to see how the development of geolibraries evolves. It is perhaps, one of my more favourite concepts with respect to GIScience.
Andrew
Geolibraries simplifying future academic research
Thursday, March 15th, 2012Goodchild suggests in Fuzzy Spatial Queries in Digital Spatial Data Libraries that the lat/long coordinate systems should only be used for areas that are lacking place names and named features. (Firstly I would argue that there are very few nomads academically publishing works from the Sahara), but more importantly, the issue of ontologies and standardization of labels arises once again. An article written in, let’s say Japan about Italy will have a completely different label than one in Canada, written about Italy. An English person would reference his or her work as a topic in Italy, while a Japanese academic would write that their subject also occurs in ????. If Goodchild is planning on writing a program, or interface, I will suggest that he use a coordinate system, and have his program group and aggregate the location of topics or footprints based on these coordinates. How does Goodchild plan to deal with international, multi-lingual academic publications?
Goodchild also poses the idea of searching by area. He suggests that we should be able to search by more than just topic and author; we should search by place as well. I think that the user should be able to search by region of interest (of the topic), region of origin, or both. If both origin and subject are georeferenced I see the possibility to create something more dynamic than this simple query .What if, in a Google Earth-like interface, we could also offer a visualized network (as we can visualize the flight-paths of commercial airplanes) of who the author has cited in a specific paper, and in another search criteria visualize what other articles have cited the article in return. Instead of rifling through Bibliographies and Works Cited pages, one (or two) simple click(s), could potentially visualizes all related articles on a map. Research simplified!
Andrew
Fuzzy Spatial Data Queries and What It Means for Government
Thursday, March 15th, 2012To be honest, I’d been at a loss for what to say differently about the second Goodchild et. al. article that I didn’t already say in regard to his book chapter. Then I began to think about Cyberinfrastructure’s post and his ideas about how uncertainty in spatial data queries can be determined by different types of scale (query scale, the segmentation scale, the data analysis scale, visualization scale) and how this problem can change with different levels of scale in and differing levels of uncertainty. Yet boiling the concept of this article down just to these abstract concepts didn’t help me in thinking about where this problem really matters – a matter Goodchild is concerned with when he talks about users of these data libraries.
So, I turned to YouTube. Don’t worry about watching the whole video.
As this video shows, users such as the government utilize geospatial data libraries quite frequently with a whole plethora of new uses. This form of uncertainty can really hinder efforts to modernize government and provide new services (impacting users like you and me).
An example from the film, when a dispatcher uses “On-Demand Pick-up” to dispatch a driver to someone who needs a ride, they better be sure their computer is picking up the same neighborhood as the caller is requesting from. If not, then they could be sending a driver from too far away to pick the person up. But how does this dispatcher get the caller to define a concrete place rather than abstract, vernacular-defined place name? It may seem just a simple question of language and communication skills. Perhaps it is.
But take another example from the film, where city administrators are able to provide real-time information to bus riders on the location of buses. How do they know what scale to provide this information to bus riders at? What if the user requires two bus lines to get where they are going? What happens if this data isn’t provided at a large enough scale to understand the placement of buses? A moot point, perhaps, as the bus will come when it comes. But certainly an important question for the people applying these GIS systems which rely on data libraries about the geographic areas where they operate. This becomes even more important when you think about technology such as LIDAR that operates at even larger scales and the methods used to define such scales of operation.
–ClimateNYC
Gazetteer Issues and Interoperability
Thursday, March 15th, 2012I’ve been thinking about “cyberinfrastructure” and “madskiier’s” posts discussing the difficulties of incorporating an appropriate “gazetteer” function with geolibraries and how this function might need to change rapidly online. However, I think we are also facing a much greater challenge that harkens back to our lecture on ontologies. A huge question that I have about this idea of a geolibrary stems from the various definitions different cultures might have for differing types of geographic features such as mountains. How we define such features and their boundaries will be an essential question going forward for any researchers looking into how to create a comprehensive geolibrary that can cross cultural, political and physical boundaries.
Michael F. Goodchild hints at this in Chapter 5 when he poses a number of possible research questions. In particular, I’m interested in his questions about how much and what kinds of metadata are needed to support a geolibrary (Question 5, Page 8 ) and what are the cognitive problems associated with using geolibraries (Question 7, Page 8). One of the keys to making a geolibrary useful and operable across the boundaries I mention above may be figuring out how to set standards for the data, and in supplying lots of useful information about the data. Metadata could serve this purpose, but, as Goodchild notes, the question may more be one of what system do we use to organize this data so that it maintains it’s usefulness and interoperability. Here, of course, you get deeper down the rabbit hole and have to begin thinking about who is going to host the geolibrary, what kind of infrastructure it requires, and, then, what kinds of systems it can support and where the data will come from.
This seems like a much broader question than just how do we search by place names or incorporate functionalities and parameters into such searches that can help diverse sets of users. Rather, I think we are beginning to ask fundamental questions of how do we define different parts of a geolibraries platform, it’s data types and the ways in which we interact with these data types. Questions of ontology and organization. Interestingly, there is PhD student at Xavier University who has been thinking about these questions in terms of digital libraries too – and he writes that “[Digital libraries] also pose technical and organizational interoperability challenges that must be resolved.” Find more from him here.
–ClimateNYC
The Alexandria Digital Library and Geolibraries
Wednesday, March 14th, 2012Cyberinfrastructure’s post on the design of gazetteers sparked an investigative light. Taking a test run on the Alexandria Digital Library, a search for “Northern Canada” focuses in on the majority of Newfoundland. Immediately, as a GIS user with some appreciation of its underlying principles, I was struck by the lack of transparency and feedback on how the geolibrary decided on Northern Canada as referring to Newfoundland. I tried typing in the name of several towns in the territories, northern Ontario and BC to establish a search history that pointed towards my definition of northern Ontario (to see if the engine would contextualize future results based on previous ones). No such luck.
The service seems much more oriented towards the delivery of data and is more reticent towards acknowledging the uncertainty of the gazetteer and how people have different ideas of the extents of places. Cyberinfrastructure’s post alludes to a growing and increasing diversity of users to match the need for constantly updated gazetteers. As the number of users and their purposes for the data grow, it becomes increasingly important to explicitly discuss the (compound) uncertainty in the datasets provided.
Based on initial impressions, a rudimentary system can be developed that allows for more flexible, user-defined boundaries. If a user defines an area that overlaps two formalized regions in the gazetteer, the system could return datasets for both regions involved. More control needs to be given to the user to understand how things are geolocated within the ADL and to include more contextual fields that tailor searches to the user’s preference. These issues are clearly in line with Goodchild’s 7th research concern on the cultural barriers inhibiting cognitive understanding of geolibraries. Presently, the ADL seems designed for planners that follow legal, administrative boundaries rather than for the general public user. Even simple contextual algorithms that Google uses in its search engine could be implemented to enhance the querying experience in ADL.
– Madskiier_JWong
Gazetteer and the Design of Digital Geolibraries
Wednesday, March 14th, 2012Goodchild has pointed out in his book the trend of digital geolibraries which utilize Internet and information services to emulate the services of conventional physical geolibraries. By this means, users are no longer constrained by the physical resource of conventional geolibraries. The term “gazetteer” describes functionalities that enable users to search an area with the place name, instead of pointing out the place on the base map. Generally, gazetteer contains location information about the place name, the dimension of geographic features of the location, population, environmental status, to name a few here. Users can visit geospatial information with the gazetteer, which serves as a type of meta-data.
In the section 5.6.3, Goodchild declares that the gazetteer is not likely to change rapidly, which I cannot agree here. For example, GeoWEB is coined as platform for geospatial information exchange, where information can be updated frequently. Therefore, the corresponding gazetteer should also be updated accordingly, since the outdated gazetteers can lead to failures in geospatial information indexing, searching and retrieving.
Digital geolibraries should provide functionalities to help user to access the gazetteer they need, or machine learning algorithms to fill the missing data in user’s input or searching criteria. Nowadays, the users of GIS are no longer research scientists or people with GIS expertise, so we should pay careful attention to the design of digital geolibraries. Sometimes, fuzzy reasoning should be applied in the design of gazetteers, which can present the geospatial information that are related to the user’s search at a reasonable scale. But how to define such a reasonable scale is a great challenge in the design of digital geolibraries.
–cyberinfrastructure
Scale, Uncertainty, and Spatial Data Libraries
Wednesday, March 14th, 2012In the paper published by Goodchild et al. in 1998, authors presented the definition of spatial data libraries and demonstrated how user access the information by specifying multidimensional keys. Footprint was studied in details and authors also demonstrated how to model fuzzy regions in spatial data libraries. The corresponding implementations were discussed, as well as the visualization. Finally, the goodness of fit was delineated.
I find that the fuzzy modeling is directly related to the previous topics in our class, scale and uncertainty analysis. Most of the geospatial information in the spatial data libraries is modeled with probability, which contains uncertainty. But the magnitude of the uncertainty is largely (not completely) determined by the scale, including the query scale, the segmentation scale, the data analysis scale, visualization scale and others. Therefore, fuzzy modeling may change with respect to different scale and uncertainty.
For example, if we request the spatial information about “south China” in the CHGIS digital GIS library of Harvard University, the uncertainty in the footprint “south China” will cause unexpected results. Since there is no standard interpretation of “south China”, the places that different users choose to represent “south China” maybe different from each other to large extent. Moreover, since the scale in “south China” is not clearly specified, one may choose a city, a province, or even several provinces to represent “south China”. Therefore, we can see both scale and uncertainty play pivotal role in spatial data library queries, which should be taken into consideration with the design of spatial data libraries.
–cyberinfrastructure
Hockey v. Hockey Stick
Tuesday, March 13th, 2012Canadian hockey may be disappearing but climate change hockey stick remains. Unfortunately.
Kudos to Concordia U. and fellow member of GEC3, Damon Matthews, who is an author of the study, Observed decreases in the Canadian outdoor skating season due to recent winter warming in Environmental Research Letters.
Visualization of tsunami spread
Monday, March 12th, 2012NASA’s geospatial model of the spread of Tohoku-oki tsunami. Another great example of how GIS is more than static pictures.